Building a fault tolerant network infrastructure for your company.

In the previous articles we solved the problems created by unmanaged network hardware. In this article we begin a series for "novice professionals", build fault-tolerant network based on expensive equipment with more good features :)
There is a task to create a network in which is no single point of failure. All commutators are connected to at least two links to two other commutators, and all the servers are connected to two commutators. At the moment the scheme is not contains channels to the internet, VPN channels and telephony, redundancy of the channels will be considered in the future. To complicate the our scheme, we have in the network equipment of different brand names. It good equipment, but different, is not fully compatible for some protocols. It will be Cisco and HP ProCurve. Sometimes it happens: ready for Cisco 6000, then communicate to you, that will be Huawei instead of Cisco, and get as result HP ProCurve... ;)
Using equipment from different brands in the network - not the best idea! We must avoid a zoo in network equipment. But if it happened, you have be able to configure :) In fact, our scheme does not hide the big problems.. First, the ProCurve is good equipment, and all the basic LAN entirely on HP, and Cisco commutators only perform additional functions, and will not perform key tasks. We should not have many problems during the project.
Of course, I devoted fan of Cisco. It is known that who love VTP, HSRP and EIGRP, who with tears and pain uses GVRP, VRRP and OSPF :)
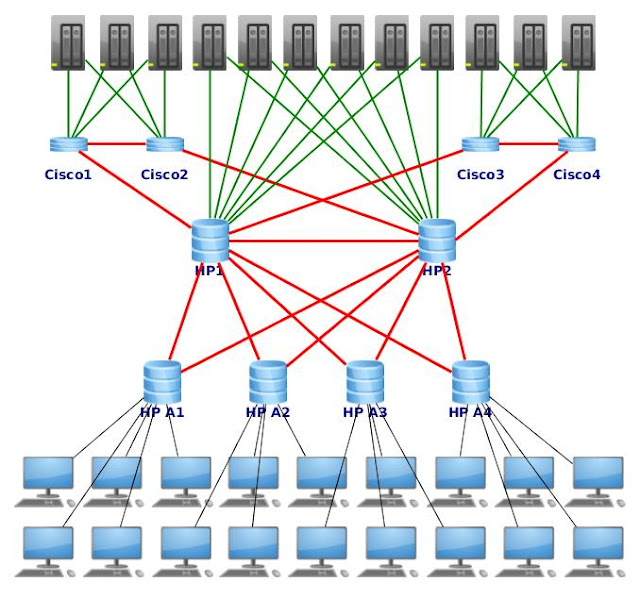
Cisco equipment are not young, but Gigabit. HP ProCurve is new and modern, all with links of 10G, and HP will be the main core of the network. Cisco use as a additional equipment, for various servers that do not generate a lot of traffic. Cisco and HP also connected through multiple trunks, though without excess.

Part 1: Spanning Tree Protocol. MSTP on HP ProCurve
In the previous articles we solved the problems created by unmanaged network hardware. In this article we begin a series for "novice professionals", build fault-tolerant network based on expensive equipment with more good features :)
There is a task to create a network in which is no single point of failure. All commutators are connected to at least two links to two other commutators, and all the servers are connected to two commutators. At the moment the scheme is not contains channels to the internet, VPN channels and telephony, redundancy of the channels will be considered in the future. To complicate the our scheme, we have in the network equipment of different brand names. It good equipment, but different, is not fully compatible for some protocols. It will be Cisco and HP ProCurve. Sometimes it happens: ready for Cisco 6000, then communicate to you, that will be Huawei instead of Cisco, and get as result HP ProCurve... ;)
Using equipment from different brands in the network - not the best idea! We must avoid a zoo in network equipment. But if it happened, you have be able to configure :) In fact, our scheme does not hide the big problems.. First, the ProCurve is good equipment, and all the basic LAN entirely on HP, and Cisco commutators only perform additional functions, and will not perform key tasks. We should not have many problems during the project.
Of course, I devoted fan of Cisco. It is known that who love VTP, HSRP and EIGRP, who with tears and pain uses GVRP, VRRP and OSPF :)
This is our network scheme:

Cisco equipment are not young, but Gigabit. HP ProCurve is new and modern, all with links of 10G, and HP will be the main core of the network. Cisco use as a additional equipment, for various servers that do not generate a lot of traffic. Cisco and HP also connected through multiple trunks, though without excess.
- We collect, assemble, connect, turn on, make the basic settings!
- All additional links between commutators must be physically disabled, until so long we not set up Spanning Tree. Otherwise many loops will kill our network.
- Configure GVRP, and sadness without beautiful VTP :)
- Permission is granted an identical list of VLAN's on all tanks between commutators! The identity is necessary that the STP would not paralize our network by prohibiting VLAN on permitted for this VLAN trunks, and allowing on prohibited trunks.
- Configure virtual IP VRRP on HP1 and HP2, for users VLAN's on the different floors. The default gateway for users must be alive always, if at least one of these HP1 and HP2 is working. Oh, where are you, HSRP ?:)
Configure Spanning Tree on HP ProCurve.
We will configure MSTP, because it is the most logical choice for a large network with a large number of VLAN. In MSTP VLAN's can be divided per "instances", and how many instances you describe, the same number of processes will be. In PVST the number of processes is equal to the number VLAN's in your network. Memory will spend the more, than more you have a VLAN. For example, in the case of 100 VLAN's, you will have 100 processes - it's horror.
Although we configure a ProCurve, but will use the recommendations to configure MSTP from Cisco. Cisco recommends that you use the same "region" in all your network, the minimum number of instances, and set up the priorities for the "root bridge". If you do not know what is "region", "root bridge", and "instances" it is necessary to first read this: Wikipedia: Spanning Tree Protocol - This will help you understand everything :)
Also highly recommend advance to divide the entire possible range of a VLAN on "instances"! Because each following change "instance" later (when you have a working network), will lead to a recalculation topology of the network and unpleasant stop network work. And if "instances" become different on the commutators, all in general will fall, and topology recalculated into a single "instance" 0 to communicate between the commutators with do not match settings.
So, start! Create two instance, given the fact that the main links between commutators in pairs, and the number of instances more than the number of links it makes no sense. We confirm that the spanning tree is disabled and we start the configuration:
Configure root HP1:
Set up the name of the region MSTP. It must be the same throughout the network:
spanning-tree config-name "H2SO4"
Config revision number must be the same in all network:
spanning-tree config-revision 1
I divide all VLAN on two "instances" according to the load on them in my network. Distributing the load evenly between instances:
spanning-tree instance 1 vlan 1-35 101 111-500 1001-4094
spanning-tree instance 2 vlan 36-100 102-110 501-1000
This commutator will be as root for instance 1:
spanning-tree instance 1 root primary
In general priority of the commutator, this root bridge in spanning tree region:
spanning-tree priority 1
Configure root HP2:
spanning-tree config-name "H2SO4"
spanning-tree config-revision 1
spanning-tree instance 1 vlan 1-35 101 111-500 1001-4094
spanning-tree instance 2 vlan 36-100 102-110 501-1000
Everything here is the same as for HP1, but it has root for instance 2, and the priority of the root bridge in the region lower: 2
spanning-tree instance 2 root primary
spanning-tree priority 2
Configuring the commutators on the floors HP Ax:
spanning-tree config-name "H2SO4"
spanning-tree config-revision 1
spanning-tree instance 1 vlan 1-35 101 111-500 1001-4094
spanning-tree instance 2 vlan 36-100 102-110 501-1000
There must be the same configuration as for HP1 and HP2, but do not set any priorities. This commutators for users on the floors, it are a low priority.
Enable spanning tree on all Commutators:
spanning-tree enable
After entering this command, you lose the connection to the commutator until miscalculated Spanning Tree topology and all ports are enabled. After that we can connect additional links between commutators and wait for activation :)
All setting on HP ProCurve is completed! We can now see the statistics in the console of the commutators :)
So, we look at the HP1:
sh spanning-tree
Multiple Spanning Tree (MST) Information
STP Enabled : Yes
Force Version : MSTP-operation
IST Mapped VLANs : 1025-4094
Switch MAC Address : 001871-b6a000
Switch Priority : 32768
Max Age : 20
Max Hops : 20
Forward Delay : 15
Topology Change Count : 9
Time Since Last Change : 87 secs
CST Root MAC Address : 001871-b6a000
CST Root Priority : 32768
CST Root Path Cost : 0
CST Root Port : This switch is root
IST Regional Root MAC Address : 001871-b6a000
IST Regional Root Priority : 32768
IST Regional Root Path Cost : 0
IST Remaining Hops : 20
Set up the name of the region MSTP. It must be the same throughout the network:
spanning-tree config-name "H2SO4"
Config revision number must be the same in all network:
spanning-tree config-revision 1
I divide all VLAN on two "instances" according to the load on them in my network. Distributing the load evenly between instances:
spanning-tree instance 1 vlan 1-35 101 111-500 1001-4094
spanning-tree instance 2 vlan 36-100 102-110 501-1000
This commutator will be as root for instance 1:
spanning-tree instance 1 root primary
In general priority of the commutator, this root bridge in spanning tree region:
spanning-tree priority 1
Configure root HP2:
spanning-tree config-name "H2SO4"
spanning-tree config-revision 1
spanning-tree instance 1 vlan 1-35 101 111-500 1001-4094
spanning-tree instance 2 vlan 36-100 102-110 501-1000
Everything here is the same as for HP1, but it has root for instance 2, and the priority of the root bridge in the region lower: 2
spanning-tree instance 2 root primary
spanning-tree priority 2
Configuring the commutators on the floors HP Ax:
spanning-tree config-name "H2SO4"
spanning-tree config-revision 1
spanning-tree instance 1 vlan 1-35 101 111-500 1001-4094
spanning-tree instance 2 vlan 36-100 102-110 501-1000
There must be the same configuration as for HP1 and HP2, but do not set any priorities. This commutators for users on the floors, it are a low priority.
Enable spanning tree on all Commutators:
spanning-tree enable
After entering this command, you lose the connection to the commutator until miscalculated Spanning Tree topology and all ports are enabled. After that we can connect additional links between commutators and wait for activation :)
All setting on HP ProCurve is completed! We can now see the statistics in the console of the commutators :)
So, we look at the HP1:
sh spanning-tree
Multiple Spanning Tree (MST) Information
STP Enabled : Yes
Force Version : MSTP-operation
IST Mapped VLANs : 1025-4094
Switch MAC Address : 001871-b6a000
Switch Priority : 32768
Max Age : 20
Max Hops : 20
Forward Delay : 15
Topology Change Count : 9
Time Since Last Change : 87 secs
CST Root MAC Address : 001871-b6a000
CST Root Priority : 32768
CST Root Path Cost : 0
CST Root Port : This switch is root
IST Regional Root MAC Address : 001871-b6a000
IST Regional Root Priority : 32768
IST Regional Root Path Cost : 0
IST Remaining Hops : 20
HP1, as prescribed for it, became a root in the MSTP region.
sh spanning-tree instance 1
E1 10GbE-SR 2000 128 Designated Forwarding 001b3f-c1a800
E2 10GbE-SR 2000 128 Designated Forwarding 001b3f-c1a800
E3 10GbE-SR 2000 128 Designated Forwarding 001b3f-c1a800
E4 Auto 128 Disabled Disabled
F1 10GbE-SR 2000 128 Designated Forwarding 001b3f-c1a800
F2 10GbE-SR 2000 128 Designated Forwarding 001b3f-c1a800
F3 Auto 128 Disabled Disabled
F4 Auto 128 Disabled Disabled
sh spanning-tree instance 2
E1 10GbE-SR 2000 128 Alternate Blocking 001b3f-582100
E2 10GbE-SR 2000 128 Alternate Blocking 001b3f-57c800
E3 10GbE-SR 2000 128 Alternate Blocking 0019bb-11ac00
E4 Auto 128 Disabled Disabled
F1 10GbE-SR 2000 128 Alternate Blocking 0019bb-0e2b00
F2 10GbE-SR 2000 128 Root Forwarding 001871-b6a000
F3 Auto 128 Disabled Disabled
F4 Auto 128 Disabled Disabled
E1 10GbE-SR 2000 128 Designated Forwarding 001b3f-c1a800
E2 10GbE-SR 2000 128 Designated Forwarding 001b3f-c1a800
E3 10GbE-SR 2000 128 Designated Forwarding 001b3f-c1a800
E4 Auto 128 Disabled Disabled
F1 10GbE-SR 2000 128 Designated Forwarding 001b3f-c1a800
F2 10GbE-SR 2000 128 Designated Forwarding 001b3f-c1a800
F3 Auto 128 Disabled Disabled
F4 Auto 128 Disabled Disabled
sh spanning-tree instance 2
E1 10GbE-SR 2000 128 Alternate Blocking 001b3f-582100
E2 10GbE-SR 2000 128 Alternate Blocking 001b3f-57c800
E3 10GbE-SR 2000 128 Alternate Blocking 0019bb-11ac00
E4 Auto 128 Disabled Disabled
F1 10GbE-SR 2000 128 Alternate Blocking 0019bb-0e2b00
F2 10GbE-SR 2000 128 Root Forwarding 001871-b6a000
F3 Auto 128 Disabled Disabled
F4 Auto 128 Disabled Disabled
In instance 2, all ways to the floors commutators labeled as alternative and closed.
Look at HP Ax located on the floors:
sh spanning-tree ins 1
L1 10GbE-SR 2000 128 Root Forwarding 001b3f-c1a800
L2 10GbE-SR 2000 128 Alternate Blocking 001871-b6a000
sh spanning-tree ins 2
L1 10GbE-SR 2000 128 Designated Forwarding 001b3f-582100
L2 10GbE-SR 2000 128 Root Forwarding 001871-b6a000
Result: instance 2 is blocked by HP1 and comes to commutators located on the floors from HP2. Commutators located on the floors block instance 1 towards HP2, and receive it from HP1. The load is distributed across the two links, which we actually wanted :) And need second trunk between HP1 and HP2 :)
Our scheme. Instances 1 is marked as blue, instance 2 marked as red:

Well, MSTP between the HP we raised, the next time we try to connect Cisco Catalyst to this scheme :)







